题目分两大部分,第一部分是不定项选择题,题目有25道,第二部分是问答题,题目有3道。
选择题
问题1
同事小鹅在训练深度学习模型时发现训练集误差不断减少,测试集误差不断增大,以下解决方法错误的是
A. 数据增强
B. 增加网络深度
C. 提前停止训练
D. 添加dropout
问题2
以下关于鞍点上的Hessian矩阵的描述哪个是正确的
A. 正定矩阵
B. 负定矩阵
C. 半正定矩阵
D. 都不对
问题3
在最佳情况下,快速排序的运行时间复杂度是
A. $O(1)$
B. $O(N)$
C. $O(N \log N)$
D. $O(N^2)$
问题4
以下图像为深度神经网络的激活函数的函数图像,最有可能发生梯度消失的是:
A. 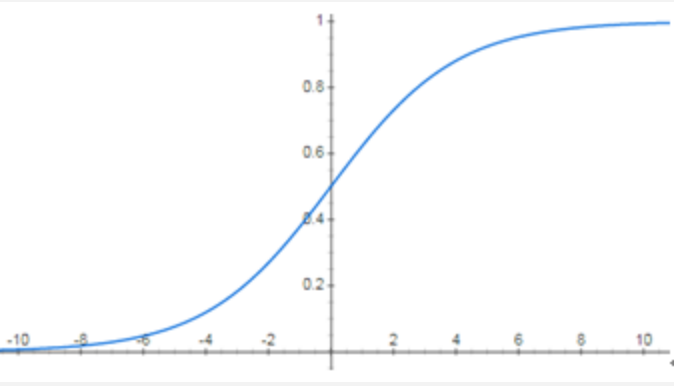
B. 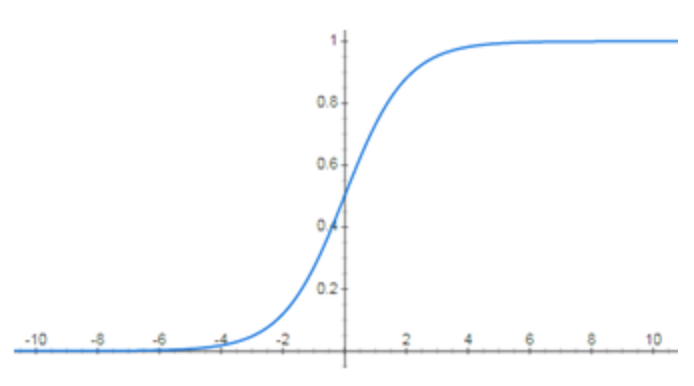
C. 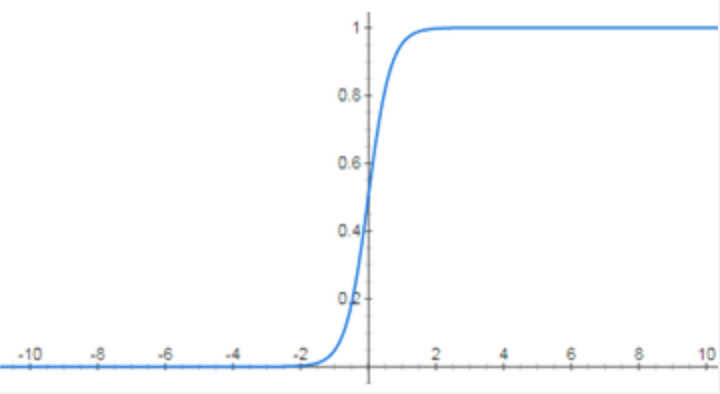
D. 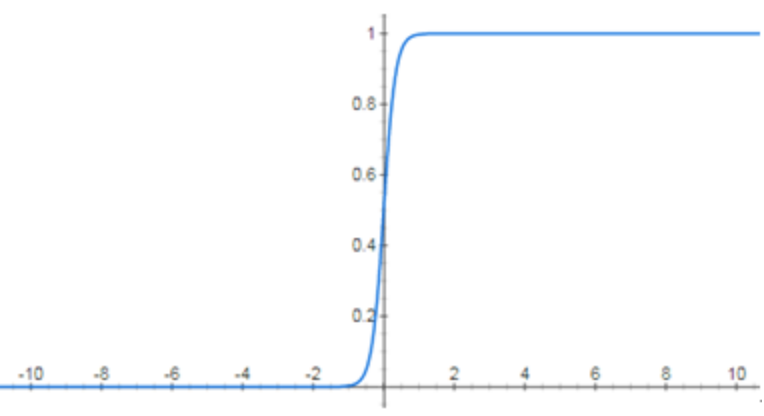
问题5
使用冒泡排序对 [5 7 0 9 2 3 1 4] 进行从小到大排序,一共需要交换多少次
A. 15
B. 16
C. 17
D. 18
问题6
《绝地求生》游戏中,共有1-3三个等级的头盔,1-3三个等级的防弹衣。假设你从无头盔、无防弹衣开始,每次只捡起没有的装备,或将低等级的装备换成高等级的对应装备,那么达到三级头盔、三级防弹衣,总共有多少种方法? (比如用(x, y)表示当前(头盔,防弹衣)的级别,0为无对应装备,则(0, 0)->(1, 0)->(1, 3)->(3, 3)为一种方法)
A. 6
B. 20
C. 64
D. 106
问题7
以下几种优化方法中,哪种对超参数最不敏感
A. SGD (stochastic gradient descent)
B. BGD (batch gradient descent)
C. Adadelta
D. Momentum
问题8
关于时间复杂度下列说法错误的是
A. 二叉树插入操作的时间复杂度为 $O(\log N)$
B. 堆排序时间复杂度为 $O(N \log N)$
C. 希尔排序时间复杂度为 $O(N^{\frac{7}{5}})$
D. 桶排序最坏情况下时间复杂度为 $O(N^2)$
问题9
设总体 $X$ 在区间 $[-1, 1]$ 上服从均匀分布,已知样本 $X_1, X_2, \ldots, X_n$ 的样本均值 $E(X)$ 和样本方差 $D(X)$,则 $D(\bar{X}) = $
A. $0$
B. $\frac{1}{3}$
C. $\frac{1}{3} n$
D. $3$
问题10
设随机变量 $X$ 满足:$E(X) = \mu$,$D(X) = \sigma^2$,则由切比雪夫不等式,有 $P(\vert X - \mu | \ge 4 \sigma) \le$
A. $\frac{1}{4}$
B. $\frac{1}{2}$
C. $\frac{1}{16}$
D. $\frac{1}{8}$
问题11
对 $n$ 个观测样本点 $(x, y)$ 进行无截距的线性回归拟合,使得残差平方和最小,回归方程为 $y=kx$,则可推导出回归系数 $k$ 为?
A. $k = \frac{\sum_{i=0}^n x_i y_i - n \bar{x} \bar{y}}{\sum_{i=0}^n x_i^2 - n \bar{x}^2}$
B. $k = \frac{\bar{y}}{\bar{x}}$
C. $k = \frac{\sum_{i=0}^n x_i y_i }{\sum_{i=0}^n x_i^2}$
D. 均不正确
问题12
一生产线生产的产品成箱包装,假设每箱平均重50kg,标准差为3kg。若用最大载重量为5000kg的汽车来承运,试用中心极限定理计算每辆车最多装多少箱,才能保证汽车不超载的概率大于0.84 (设 $\Phi(1) =0.84$,其中 $\Phi(x)$ 是标准正太分布 $N(0, 1)$ 的分布函数)
A. 最多装96箱
B. 最多装97箱
C. 最多装98箱
D. 最多装99箱
问题13
分层抽样方法,在下面哪种情况下是比较合适的选择
A. 研究的总体非常小
B. 在调研中希望了解不同子群体的差异
C. 总体中只有一部分样本是可以调研的
D. 没有先验的总体信息
问题14
在无线网络中分别以概率0.6和概率0.4,发出信号”0”和”1”,由于通讯系统受到干扰,当发送”0”时,接收方以概率0.8收到”0”,概率0.2收到”1”,当发送”1”时,接收方以概率0.9收到”1”,概率0.1收到”0”,则下列说法正确的是
(1) 收到信号”0”的概率是0.52
(2) 收到信号”0”时,发出信号也是”0”的概率是12/13
A. (1) 和(2)都错误
B. (1)正确,(2)错误
C. (1)错误,(2)正确
D. (1)和(2)都正确
问题15
已知 $f(x) = 3x^2 + 4x f’(x)$,则 $f’(0) =$
A. -8
B. -16
C. -24
D. -32
问题16
函数 $f(x)$ 在 $x=b$ 处导数存在,为 $f’(b)$。则 $\lim_{h \to 0} \frac{f(b + 4h) - f(b - 2h)}{2h}$
A. $f’(b)$
B. $\frac{1}{3} f’(b)$
C. $3 f’(b)$
D. $2 f’(b)$
问题17
对于矩阵 $A$,已知 Rank(A) = 3,以下哪项是K可能的值?
$$
A = \begin{bmatrix}
K & 1 & 1 & 1 \
1 & K & 1 & 1 \
1 & 1 & K & 1 \
1 & 1 & 1 & K
\end{bmatrix}
$$
A. K=-1
B. K=-3 或 K=-1
C. K=-3
D. k=3 或 K=-1
问题18
下面哪种情况是用图的深度优先遍历方法得到的结果
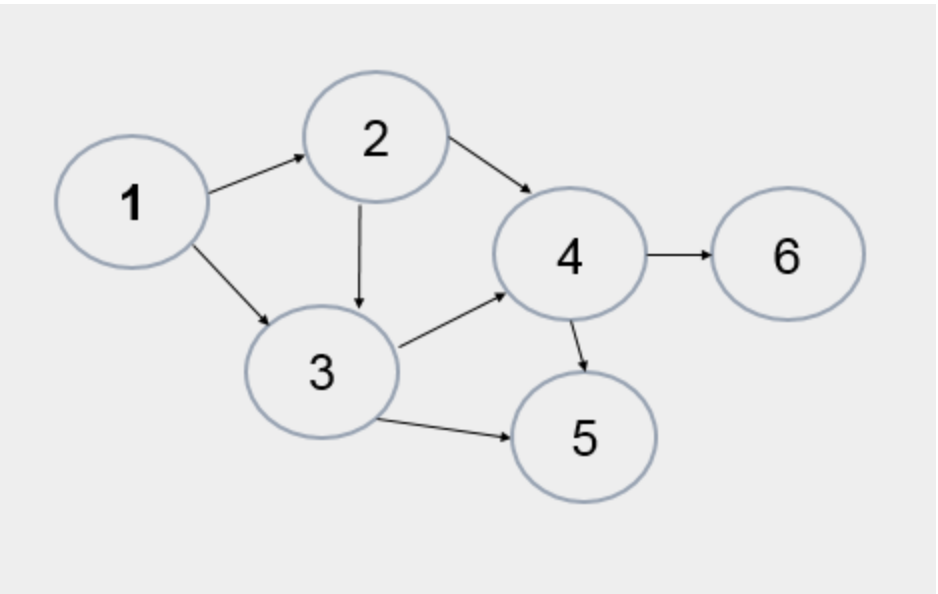
A. 1, 2, 3, 4, 5, 6
B. 1, 2, 4, 6, 5, 3
C. 1, 3, 5, 2, 4, 6
D. 1, 3, 2, 5, 4, 6
问题19
$Ax = 0$ 中 $A$ 是以下参数,哪个方程组有非零解?
A
$$
\begin{bmatrix}
-3 & 4 & -8 \
-2 & 5 & 5
\end{bmatrix}
$$
B
$$
\begin{bmatrix}
2 & -5 & 8 \
-2 & -7 & 1\
4 & 2 & 7
\end{bmatrix}
$$
C
$$
\begin{bmatrix}
-3 & 4 & -8 \
-2 & 5 & 4
\end{bmatrix}
$$
D
$$
\begin{bmatrix}
2 & -5 & 9 \
-2 & -7 & 1 \
4 & 2 & 7
\end{bmatrix}
$$
问题20
给一个整数数组,需要快速查找指定的一个整数是否在其中,需要哪些操作
A. 二分查找
B. 排序
C. 排序,二分查找
D. 顺序遍历
问题21
若 $f(x) = \int_{x}^{x^3} e^{-t^2} dt$,则 $f’(x) =$
A. $3x^2e^{-x^6} - e^{-x^2}$
B. $2x e^{-x^6} - e^{-x}$
C. $2x e^{-x^4} - e^{-x^2}$
D. $3x^2 e^{-x^6} - e^{-x}$
问题22
给定一组数据,以下哪种方法可以检验数据是否服从正态分布?
A. Q-Q图
B. Wilcoxon符号秩检验
C. K-S检验
D. t检验
问题23
关于秩统计量,下列说法正确的是:
A. 需要总体分布符合特定分布
B. 需要总体参数满足一定条件
C. 不需要总体分布符合特定分布
D. 检验统计量与总体分布的具体参数无关
问题24
下列关于协方差和相关系数的说法,正确的是?(假定X、Y是两个变量)
A. 协方差的正或负,反映两个变量X、Y是同向变化或反向变化
B. 协方差的绝对值,反映两个变量X、Y同向或反向变化的程度
C. 两个变量的相关系数是消除量纲和标准化之后的特殊的协方差
D. 相关系数反应两个变量每单位变化的相似程度
问题25
克莱姆法则是线性代数中一个关于求解线性方程组的定理。对于一个具有N个方程、N个未知数的线性方程组,下列说法正确的是:
A. 当方程组的系数行列式不等于零时,则方程组一定有解
B. 如果方程组有两个不同的解,那么方程组的系数行列式必定等于零
C. 如果方程组的系数行列式等于零,那么方程组一定无解
D. 当方程组的系数行列式不等于零时,则方程组可能有多组解
问答题
问题1
试论述机器学习模型中的偏差 (Bias) 和方差 (Variance),并说明各种情况下的解决办法。
问题2
请简诉数理统计中假设检验的基本步骤。
问题3
假如你现在能够拿到微信用户的定位信息 (位置信息),比如用户每一分钟会上传自己的位置到后台。请发挥你的想象力,这些定位数据能够做哪些事情,可以创造哪些社会价值。
