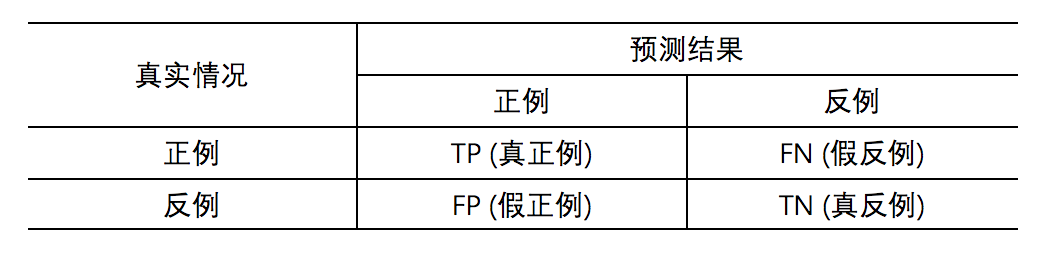
fps = [] tps = [] for threshold in thresholds: # 大于等于阈值判定为 1 (正类),否则为 0 (负类) y_predict = [1 if i >= threshold else 0 for i in y_score] # 预测值是否等于真实值 result = [i == j for i, j in zip(y_true, y_predict)] # 预测值是否为 1 (正类) positive = [i == 1 for i in y_predict]
# 预测为正类且预测错误 fp = [(not i) and j for i, j in zip(result, positive)].count(True) # 预测为正类且预测正确 tp = [i and j for i, j in zip(result, positive)].count(True)
Give a string s, count the number of non-empty (contiguous) substrings that have the same number of 0’s and 1’s, and all the 0’s and all the 1’s in these substrings are grouped consecutively.
Substrings that occur multiple times are counted the number of times they occur.
Example 1:
1 2 3 4 5 6 7
Input: "00110011" Output: 6 Explanation: There are 6 substrings that have equal number of consecutive 1's and 0's: "0011", "01", "1100", "10", "0011", and "01".
Notice that some of these substrings repeat and are counted the number of times they occur.
Also, "00110011" is not a valid substring because all the 0's (and 1's) are not grouped together.
Example 2:
1 2 3
Input: "10101" Output: 4 Explanation: There are 4 substrings: "10", "01", "10", "01" that have equal number of consecutive 1's and 0's.
#include <iostream> #include <string> #include <cstring> using namespace std;
class Solution { public: int firstUniqChar(string s) { if (s.size() == 0) return -1; else if (s.size() == 1) return 0;
/* letters[i] * -1 means letter repeat * 0 means letter not appear * > 0 means position of letter in string (index starts from 1) */ int letters[26]; int pos;
memset(letters, 0, sizeof(letters)); for (int i=0; i<s.size(); i++) { pos = s[i] - 'a'; if (letters[pos] > 0) letters[pos] = -1; else if (letters[pos] == 0) letters[pos] = i + 1; }
int ret = -1; for (int i=0; i<26; i++) { if (letters[i] > 0) { if (ret == -1) ret = letters[i] - 1; else if (ret > letters[i] - 1) ret = letters[i] - 1; } }
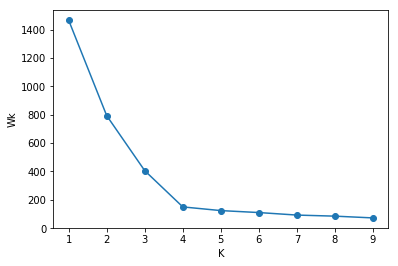
cluster the observed data, varying the total number of clusters from $K=1, 2, \ldots, K_{\text{max}}$, and giving within-dispersion measures $W_K, K=1, 2, \ldots, K_{\text{max}}$
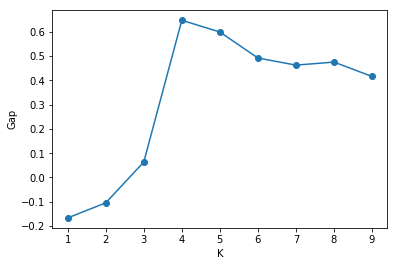
generate $B$ reference data sets and cluster each one giving within-dispersion measures $W_{Kb}$, $b=1,2, \ldots, B$, $K=1, 2, \ldots, K_{\text{max}}$. Compute the gap statistic $$ \text{Gap}(K) =\frac{1}{B} \sum_{b=1}^B \log(W_{Kb}) - \log(W_K) $$
let $\bar{w} = \frac{1}{B} \sum_{b=1}^B \log(W_{Kb})$, compute the standard deviation $$ \text{sd}K = \left[ \frac{1}{B} \sum{b=1}^B (\log(W_{Kb}) - \bar{w})^2 \right]^{\frac{1}{2}} $$ and define $s_K = \text{sd}_K \sqrt{1 + \frac{1}{B}}$
choose the number of clusters as the smallest $K$ such that $\text{Gap(K)} \ge \text{Gap(K+1)} - s_{K+1}$
def calculate_Wk(data, centroids, cluster): K = centroids.shape[0] wk = 0.0 for k in range(K): data_in_cluster = data[cluster == k, :] center = centroids[k, :] num_points = data_in_cluster.shape[0] for i in range(num_points): wk = wk + np.linalg.norm(data_in_cluster[i, :]-center, ord=2) ** 2
return wk
def bounding_box(data): dim = data.shape[1] boxes = [] for i in range(dim): data_min = np.amin(data[:, i]) data_max = np.amax(data[:, i]) boxes.append((data_min, data_max))
''' 写法1 log_Wks = np.zeros(num_K) gaps = np.zeros(num_K) sks = np.zeros(num_K) for ind_K, K in enumerate(K_range): cluster_centers, labels, _ = cluster_algorithm(data, K) log_Wks[ind_K] = np.log(calculate_Wk(data, cluster_centers, labels))
# generate B reference data sets log_Wkbs = np.zeros(B) for b in range(B): for i in range(num_points): for j in range(dim): data_generate[i][j] = \ np.random.uniform(boxes[j][0], boxes[j][1]) cluster_centers, labels, _ = cluster_algorithm(data_generate, K) log_Wkbs[b] = \ np.log(calculate_Wk(data_generate, cluster_centers, labels)) gaps[ind_K] = np.mean(log_Wkbs) - log_Wks[ind_K] sks[ind_K] = np.std(log_Wkbs) * np.sqrt(1 + 1.0 / B) '''
''' 写法2 ''' log_Wks = np.zeros(num_K) for indK, K in enumerate(K_range): cluster_centers, labels, _ = cluster_algorithm(data, K) log_Wks[indK] = np.log(calculate_Wk(data, cluster_centers, labels))
gaps = np.zeros(num_K) sks = np.zeros(num_K) log_Wkbs = np.zeros((B, num_K))
# generate B reference data sets for b in range(B): for i in range(num_points): for j in range(dim): data_generate[i, j] = \ np.random.uniform(boxes[j][0], boxes[j][1]) for indK, K in enumerate(K_range): cluster_centers, labels, _ = cluster_algorithm(data_generate, K) log_Wkbs[b, indK] = \ np.log(calculate_Wk(data_generate, cluster_centers, labels))
for k in range(num_K): gaps[k] = np.mean(log_Wkbs[:, k]) - log_Wks[k] sks[k] = np.std(log_Wkbs[:, k]) * np.sqrt(1 + 1.0 / B)
Tibshirani R, Walther G, Hastie T. Estimating the number of clusters in a data set via the gap statistic[J]. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 2001, 63(2): 411-423.
Given a paragraph and a list of banned words, return the most frequent word that is not in the list of banned words. It is guaranteed there is at least one word that isn’t banned, and that the answer is unique.
Words in the list of banned words are given in lowercase, and free of punctuation. Words in the paragraph are not case sensitive. The answer is in lowercase.
Example:
1 2 3 4 5 6 7 8 9 10 11 12
Input: paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." banned = ["hit"]
Output: "ball"
Explanation: "hit" occurs 3 times, but it is a banned word. "ball" occurs twice (and no other word does), so it is the most frequent non-banned word in the paragraph. Note that words in the paragraph are not case sensitive, that punctuation is ignored (even if adjacent to words, such as "ball,"), and that "hit" isn't the answer even though it occurs more because it is banned.
Note:
1 <= paragraph.length <= 1000.
1 <= banned.length <= 100.
1 <= banned[i].length <= 10.
The answer is unique, and written in lowercase (even if its occurrences in paragraph may have uppercase symbols, and even if it is a proper noun.)
paragraph only consists of letters, spaces, or the punctuation symbols !?',;.
Different words in paragraph are always separated by a space.
There are no hyphens or hyphenated words.
Words only consist of letters, never apostrophes or other punctuation symbols.
Initially, there is a Robot at position (0, 0). Given a sequence of its moves, judge if this robot makes a circle, which means it moves back to the original place.
The move sequence is represented by a string. And each move is represent by a character. The valid robot moves are R (Right), L (Left), U (Up) and D (down). The output should be true or false representing whether the robot makes a circle.
Roman numerals are represented by seven different symbols: I, V, X, L, C, D and M.
1 2 3 4 5 6 7 8
Symbol Value I 1 V 5 X 10 L 50 C 100 D 500 M 1000
For example, two is written as II in Roman numeral, just two one’s added together. Twelve is written as, XII, which is simply X + II. The number twenty seven is written as XXVII, which is XX + V + II.
Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not IIII. Instead, the number four is written as IV. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as IX. There are six instances where subtraction is used:
I can be placed before V (5) and X (10) to make 4 and 9.
X can be placed before L (50) and C (100) to make 40 and 90.
C can be placed before D (500) and M (1000) to make 400 and 900.
Given a roman numeral, convert it to an integer. Input is guaranteed to be within the range from 1 to 3999.
Example 1:
1 2
Input: "III" Output: 3
Example 2:
1 2
Input: "IV" Output: 4
Example 3:
1 2
Input: "IX" Output: 9
Example 4:
1 2 3
Input: "LVIII" Output: 58 Explanation: C = 100, L = 50, XXX = 30 and III = 3.
Example 5:
1 2 3
Input: "MCMXCIV" Output: 1994 Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.
#include <iostream> #include <string> using namespace std;
class Solution { public: int romanToInt(string s) { int num = 0; int j; char ch;
for (int i=0; i<s.size(); i++) { ch = s[i]; j = i + 1; switch (ch) { case 'I': // value 1 if (j < s.size() && (s[j] == 'V' || s[j] == 'X')) num -= 1; else num += 1; break; case 'V': // value 5 num += 5; break; case 'X': // value 10 if (j < s.size() && (s[j] == 'L' || s[j] == 'C')) num -= 10; else num += 10; break; case 'L': // value 50 num += 50; break; case 'C': // value 100 if (j < s.size() && (s[j] == 'D' || s[j] == 'M')) num -= 100; else num += 100; break; case 'D': // value 500 num += 500; break; case 'M': // value 1000 num += 1000; break; } }
return num; } };
int main() { Solution solu; string str1 = "MCMXCIV";