本文主要介绍如何将大量图片数据集合起来,然后生成一个SequenceFile,这么做的原因是避免Hadoop处理大量小文件导致性能下降。SequenceFile的key-value内容以及数据类型为:
1
2
| key : 储存图片文件名,数据类型为Text
value : 储存图片数据,数据类型为ArrayPrimitiveWritable
|
为什么要用ArrayPrimitiveWritable来存储图片数据,主要是我想将图片数据用一个int数组来存储,数组元素就是图像的像素,数据范围在[0, 255],当然,你可以使用byte数组来存储图片数据。
生成SequenceFile
实验用的图片文件为:

方法一
第一种方法就是直接使用ImageIO读取图片的所有像素,然后存储像素值到一个int数组中,最后使用ArrayPrimitiveWritable的set()函数存储图像数据。生成操作涉及遍历目录 (参考:Java获取指定目录下的所有文件) 以及读取图片像素 (参考:Java读取PGM图片)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayPrimitiveWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.awt.image.Raster;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
public class WriteImagesToSequenceFile {
public static void main(String[] args) throws IOException {
String imagesPath = "/tmp/images";
String seqPath = "/tmp/images.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(seqPath);
Text key = new Text();
ArrayPrimitiveWritable value = new ArrayPrimitiveWritable();
SequenceFile.Writer writer = null;
try {
BufferedImage image = null;
int[] pixels = null;
Raster source = null;
int width = 0;
int height = 0;
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass());
ArrayList<File> files = ListFiles.getAllFiles(imagesPath, 1);
for (File file : files) {
System.out.println("Processing " + file.getName());
image = ImageIO.read(file);
source = image.getRaster();
width = image.getWidth();
height = image.getHeight();
pixels = new int[width*height];
source.getPixels(0, 0, width, height, pixels);
key.set(file.getName());
value.set(pixels);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
|
方法二
第二种方法是编写一个MapReduce程序来生成SequenceFile,这个主要参考了<<Hadoop权威指南>> 第四版中第八章的程序SmallFilesToSequenceFileConverter,原始程序中key-value的value的数据类型为BytesWritable,这里为ArrayPrimitiveWritable。
WholeFileInputFormat类代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayPrimitiveWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class WholeFileInputFormat extends FileInputFormat<NullWritable, ArrayPrimitiveWritable> {
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<NullWritable, ArrayPrimitiveWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
WholeFileRecordReader reader = new WholeFileRecordReader();
reader.initialize(inputSplit, taskAttemptContext);
return reader;
}
}
|
WholeFileRecordReader类代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
| import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayPrimitiveWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.awt.image.Raster;
import java.io.IOException;
public class WholeFileRecordReader extends RecordReader<NullWritable, ArrayPrimitiveWritable> {
private FileSplit fileSplit;
private Configuration conf;
private ArrayPrimitiveWritable value = new ArrayPrimitiveWritable();
private boolean processed = false;
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
this.fileSplit = (FileSplit)inputSplit;
this.conf = taskAttemptContext.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!processed) {
Path file = fileSplit.getPath();
FileSystem fs = file.getFileSystem(conf);
FSDataInputStream in = null;
BufferedImage image = null;
Raster source = null;
int[] pixels = null;
int width, height;
try {
in = fs.open(file);
image = ImageIO.read(in);
source = image.getRaster();
width = image.getWidth();
height = image.getHeight();
pixels = new int[width*height];
source.getPixels(0, 0, width, height, pixels);
value.set(pixels);
} finally {
IOUtils.closeStream(in);
}
processed = true;
return true;
}
return false;
}
@Override
public NullWritable getCurrentKey() throws IOException, InterruptedException {
return NullWritable.get();
}
@Override
public ArrayPrimitiveWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() throws IOException {
}
}
|
SmallFilesToSequenceFileConverter类代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayPrimitiveWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SmallFilesToSequenceFileConverter extends Configured implements Tool {
static class SequenceFileMapper
extends Mapper<NullWritable, ArrayPrimitiveWritable, Text, ArrayPrimitiveWritable> {
private Text filenameKey;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
InputSplit split = context.getInputSplit();
Path path = ((FileSplit)split).getPath();
filenameKey = new Text(path.toString());
}
@Override
protected void map(NullWritable key, ArrayPrimitiveWritable value, Context context) throws IOException, InterruptedException {
context.write(filenameKey, value);
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null)
return -1;
job.setInputFormatClass(WholeFileInputFormat.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(ArrayPrimitiveWritable.class);
job.setMapperClass(SequenceFileMapper.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new SmallFilesToSequenceFileConverter(), args);
System.exit(exitCode);
}
}
|
补充:代码使用的JobBuilder类的代码在:https://github.com/tomwhite/hadoop-book/blob/master/common/src/main/java/JobBuilder.java
读取SequenceFile
使用Hadoop命令来读取第一个方法生成的SequenceFile内容,显示如下:

图片内容没有显示出来,只是显示了org.apache.hadoop.io.ArrayPrimitiveWritable@17497425,要显示具体内容使用下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.ArrayPrimitiveWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.util.ReflectionUtils;
import java.io.IOException;
import java.net.URI;
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = args[0]
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
while (reader.next(key, value)) {
int[] pixels = (int[])((ArrayPrimitiveWritable)value).get();
System.out.printf("%s\t:\t", key);
for (int i=0; i<10; i++)
System.out.printf("%d ", pixels[i]);
System.out.println();
}
} finally {
IOUtils.closeStream(reader);
}
}
}
|
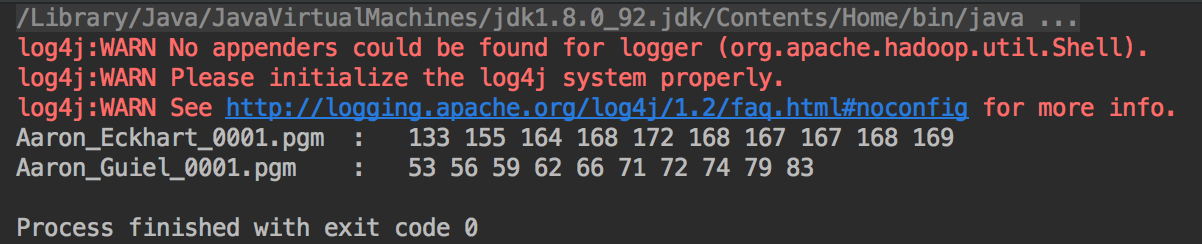
读取图片的第一行的前十个像素,显示如下:
Reference
- https://github.com/kmicinski/hadoop-class-project/blob/master/src/main/phase2/WriteImagesToSequenceFile.java