关于 Hadoop Streaming 的使用,可以参考官方网站 Hadoop Streaming。个人觉得使用Steaming这个功能,可以使用其他语言来编写MapReduce程序,相比使用Java来编写程序,工作量小了很多。
根据《Hadoop权威指南》中例子使用python来实现 Max Temperature 这个程序,要分别实现Map函数以及Reduce函数。
Map函数
1 | #!/usr/bin/env python |
Reduce函数
1 | #!/usr/bin/env python |
本文用到的文件如下:

其中 1901.txt为数据文件,max_temperature_map.py定义了Map函数,max_temperature_reduce.py定义了Reduce函数
定义好Map函数以及Reduce函数后,利用unix的管道将Map过程以及Reduce过程连接起来,使用下面命令
1 | $ cat 1901.txt | ./max_temperature_map.py | sort | ./max_temperature_reduce.py |
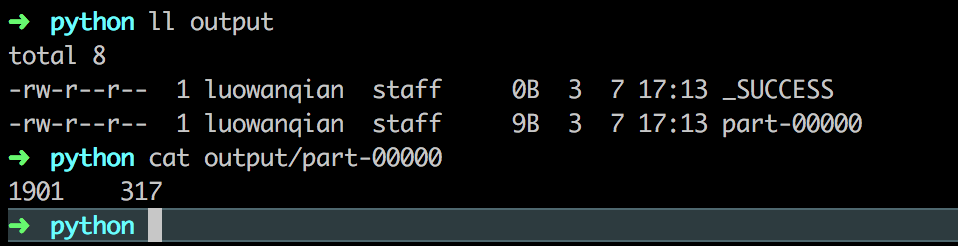
运行结果如下:

运行结果正确,此时就可以使用Hadoop的Streaming了,使用下面命令
1 | $ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.7.3.jar \ |
注意:如果文件是在本地文件系统中而不是HDFS中时,要使用 -fs file:/// 这个命令选项
运行结果保存到 output 文件夹中